Hyperparameter Tuning for Smart People: Why Optuna Beats GridSearchCV and RandomizedSearchCV

Hyperparameter tuning is a crucial step in machine learning that involves finding the optimal set of hyperparameters for a model to achieve the best performance. Traditional methods like GridSearchCV and RandomizedSearchCV have been widely used, but they come with significant limitations. In this article, we will explore these traditional methods, their drawbacks, and then introduce Optuna, a powerful tool that leverages Bayesian optimization to efficiently find the best hyperparameters. By the end, you’ll understand why Optuna has become the go-to solution for modern hyperparameter optimization.
Traditional Hyperparameter Tuning Methods
Before diving into Optuna, let’s understand the traditional methods of hyperparameter tuning and why they fall short in modern machine learning workflows.
GridSearchCV: Exhaustive but Computationally Expensive

GridSearchCV is a method that exhaustively searches through a predefined grid of hyperparameters to find the best combination. It tests every possible combination, making it thorough but potentially time-consuming. For instance, if you are tuning a Random Forest model with hyperparameters like n_estimators, max_depth, and min_samples_split, GridSearchCV will train and evaluate the model on every combination of these parameters4.
Let’s consider an example where you have three possible values for n_estimators (100, 200, 300), three for max_depth (10, 20, None), and three for min_samples_split (2, 5, 10). GridSearchCV will evaluate all 27 combinations (3x3x3) to find the best set of hyperparameters. This approach is comprehensive but can become computationally expensive as the number of hyperparameters and their possible values increase4.
While GridSearchCV guarantees finding the best combination within the defined grid, it has several drawbacks:
- It is computationally expensive, especially for models with many hyperparameters.
- It fails to leverage information from previous trials, treating each combination as independent.
- It becomes impractical for deep learning models with large hyperparameter spaces.
RandomizedSearchCV: A Smarter but Still Naive Approach
RandomizedSearchCV offers a more efficient alternative by randomly sampling a fixed number of parameter settings from specified distributions. Instead of trying every combination, it selects random combinations, which can be more efficient, especially when dealing with many parameters or large ranges 4.
Using the same Random Forest example, you might specify the same ranges for n_estimators, max_depth, and min_samples_split, but instead of trying all combinations, RandomizedSearchCV randomly selects, say, 10 combinations to evaluate. This approach is faster and often finds a good solution more quickly, but it lacks the thoroughness of GridSearchCV.
However, RandomizedSearchCV also has limitations:
- It still performs a blind search with no learning from previous trials.
- It might miss the optimal combination due to its random sampling approach.
- Performance depends on luck and the number of iterations allowed.
Limitations of Traditional Methods
Both GridSearchCV and RandomizedSearchCV have significant limitations. GridSearchCV is computationally expensive and impractical for models with many hyperparameters, such as neural networks. RandomizedSearchCV, while faster, may not find the optimal solution due to its random sampling approach 4.
In modern machine learning, we need a more intelligent approach — one that learns from past trials and optimizes efficiently. This is where Optuna comes in.
Introduction to Optuna
Optuna is a powerful hyperparameter optimization framework that uses Bayesian optimization to efficiently find the best hyperparameters. Unlike traditional methods, Optuna builds a probabilistic model of the objective function, which predicts the relationship between hyperparameters and performance. This approach allows Optuna to suggest new hyperparameters to evaluate, learning from previous results to explore the search space efficiently.

How Optuna Works
Optuna’s process can be likened to a chef trying to perfect a recipe. The chef (Optuna) starts with a set of ingredients (hyperparameters) and evaluates the dish (model performance) using a taste test (objective function). Based on past results, the chef uses a surrogate model (a probabilistic approximation of the objective function) to predict how good future dishes might be.
This iterative process involves three key components:
- Surrogate Model: This model approximates the objective function without needing to evaluate every possible combination. It helps predict how good a set of hyperparameters might be.
- Acquisition Function: This function decides which hyperparameters to try next. It balances exploration (trying new hyperparameters) and exploitation (refining known good hyperparameters) to efficiently find the optimal solution.
- Tree-structured Parzen Estimator (TPE): Unlike traditional Bayesian optimization methods that use Gaussian Processes, Optuna employs Tree-structured Parzen Estimator (TPE). TPE models the objective function by constructing two distributions:
l(x): The distribution of hyperparameters that performed well in previous trials.g(x): The distribution of hyperparameters that performed poorly.
Balancing Exploration and Exploitation
Optuna uses a combination of surrogate models and acquisition functions to manage the exploration-exploitation trade-off. The acquisition function is responsible for deciding which hyperparameters to try next, considering both the predicted performance and the uncertainty of the surrogate model.
Different acquisition functions favor different strategies:
- Expected Improvement (EI): This acquisition function favors exploitation by selecting hyperparameters that are likely to improve upon the current best performance.
- Probability of Improvement (PI): Similar to EI, PI focuses on exploitation but is less aggressive in seeking improvements.
- Upper Confidence Bound (UCB): UCB balances exploration and exploitation by selecting hyperparameters with high predicted performance and high uncertainty.
Define-by-Run and Dynamic Search Space
One of Optuna’s most powerful features is its ability to dynamically define the search space during optimization, known as “Define-by-Run.” This approach is particularly useful when you’re unsure which model or hyperparameters will work best from the start.
Imagine you have a dataset and you’re considering multiple models like SVM, XGBoost, Random Forest, and Linear Regression. Optuna treats the model choice itself as a hyperparameter, allowing it to dynamically adjust the search space based on intermediate results. As trials progress, Optuna learns which combinations of model and hyperparameters yield the best results, iteratively refining its approach.
For example, Optuna might start by exploring SVM with certain hyperparameters, then move to XGBoost based on the results, and finally focus on Random Forest if it shows promise. This dynamic approach makes Optuna highly efficient and adaptable.
Key Terms in Optuna
To understand how Optuna works, it’s essential to grasp its key terms:
Study
A Study is the entire process of finding the best hyperparameters for a model. It encompasses all trials and evaluations performed during optimization.
Trial
A trial represents a single iteration where Optuna tries out a specific combination of hyperparameters. Each trial evaluates the model’s performance with the given hyperparameters.
Trial Parameters
These are the specific hyperparameters chosen for each trial. For example, in a Random Forest model, trial parameters might include n_estimators and max_depth.
Objective Function
This function evaluates the performance of the model with the given hyperparameters. It’s essentially the metric you want to optimize, such as accuracy or loss.
Sampler
The sampler is responsible for suggesting which hyperparameters to try next based on past results. It uses Bayesian optimization to make informed decisions about the next trial parameters.
Pruning and Early Stopping
Optuna implements pruning, which stops unpromising trials early. This significantly reduces computation time by not wasting resources on hyperparameter sets that are unlikely to perform well.
For example, if a model with a particular set of hyperparameters is performing poorly after just a few epochs, Optuna can automatically terminate that trial and move on to more promising hyperparameter combinations. This is particularly valuable when training deep learning models, which can take hours or days to train5.
Advantages of Optuna
Optuna offers several advantages over traditional hyperparameter tuning methods:
Efficient Optimization
Optuna uses Bayesian optimization to efficiently explore the hyperparameter space, often finding good solutions faster than exhaustive methods. By learning from previous trials, it can focus on promising areas of the search space, saving valuable computation time.
Dynamic Search Space
Its ability to dynamically adjust the search space allows Optuna to adapt to different models and hyperparameters, making it highly flexible. This is especially useful when exploring complex model architectures or when you’re uncertain about which model will work best for your data.
Distributed Computing
By distributing trials across multiple machines, Optuna can significantly speed up the optimization process, which is crucial for complex models and large datasets. This scalability makes it suitable for enterprise-level machine learning applications.
Seamless Integration
Optuna integrates well with popular machine learning frameworks like scikit-learn, Keras, PyTorch, and XGBoost. This integration makes it easy to incorporate into existing workflows.
Common Pitfalls When Using Optuna
While Optuna is a powerful tool, there are several common pitfalls to be aware of:
Insufficient Exploration
Optuna’s Bayesian optimization can sometimes focus too quickly on exploiting known good solutions without adequately exploring the hyperparameter space. To mitigate this, consider increasing the number of trials or using different acquisition functions that favor exploration.
Inadequate Search Space Definition
Defining an appropriate search space is crucial. If the space is too large or includes irrelevant hyperparameters, optimization can become inefficient. Conversely, if the space is too small, you might miss optimal solutions.
Version Compatibility
Optuna does not support saving and reloading studies across different versions using pickle. Always ensure that you’re using the same version of Optuna for saving and loading studies.
Practical Example: Using Optuna with XGBoost
Let’s look at a simple example of using Optuna to tune an XGBoost model:

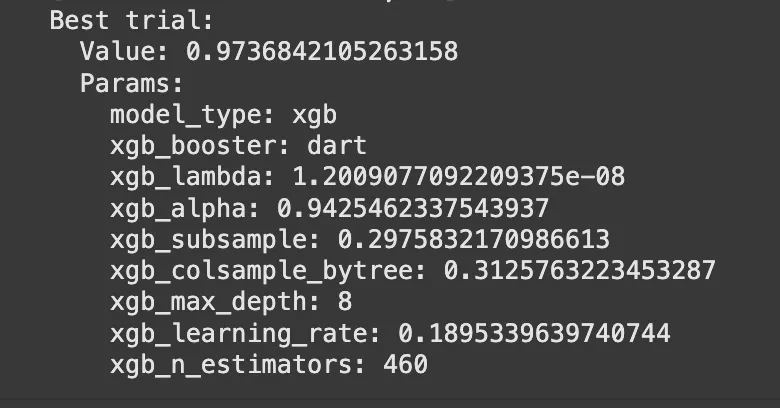
The result shows the best hyperparameters found for an XGBoost (xgb) model using Optuna. The best trial achieved a performance score of 0.9737, indicating a strong model fit.
Key Parameters:
- xgb_booster: dart → Uses the “DART” (Dropouts meet Multiple Additive Regression Trees) booster, which is useful for reducing overfitting.
- xgb_lambda: 1.2e-08 → L2 regularization term (Ridge regression), controlling complexity.
- xgb_alpha: 0.94 → L1 regularization term (Lasso regression), enforcing sparsity.
- xgb_subsample: 0.297 → Randomly samples ~30% of data per boosting iteration to prevent overfitting.
- xgb_colsample_bytree: 0.312 → Uses 31.2% of features per tree, reducing correlation between trees.
- xgb_max_depth: 8 → Controls tree depth, balancing complexity and performance.
- xgb_learning_rate: 0.1895 → High learning rate, making the model converge faster.
- xgb_n_estimators: 460 → Uses 460 trees in the boosting process.
Explanation
- Dynamic Model Selection: The
objectivefunction now includes amodel_typeparameter that allows Optuna to dynamically choose between XGBoost, Random Forest, and SVM models. This is achieved usingtrial.suggest_categorical("model_type", ["xgb", "rf", "svm"]). - Conditional Hyperparameters: Each model has its own set of hyperparameters. For instance, XGBoost has parameters like
booster,lambda, andmax_depth, while Random Forest has parameters liken_estimatorsandmax_depth. These are conditionally suggested based on the chosen model type. - Efficient Search Space: By dynamically adjusting the search space based on the model choice, Optuna efficiently explores different hyperparameter combinations without wasting trials on irrelevant parameters.
- Bayesian Optimization: Optuna uses Bayesian optimization to learn from past trials and make informed decisions about which hyperparameters to try next. This process is guided by the acquisition function, which balances exploration and exploitation.
- Pruning and Early Stopping: While not explicitly implemented in this example, Optuna supports pruning unpromising trials early, which can significantly reduce computation time.
Advantages
- Flexibility: This approach allows for easy addition or removal of models and hyperparameters, making it highly adaptable to different machine learning tasks.
- Efficiency: By dynamically selecting models and hyperparameters, Optuna reduces unnecessary evaluations, saving computation time.
- Scalability: This method can be scaled up to include more complex models and larger datasets by leveraging Optuna’s distributed computing capabilities.
Conclusion
Optuna’s ability to dynamically adjust the search space and optimize multiple models simultaneously makes it a powerful tool for hyperparameter tuning. This approach not only saves time but also ensures that the best model and its hyperparameters are found efficiently. Whether you’re working with traditional machine learning models or deep learning architectures, Optuna provides a flexible and efficient way to optimize performance.
Get to know the Author:
Karan Bhutani is a Data Scientist Intern at Synogize and a master’s student in Data Science at the University of Technology Sydney. Passionate about machine learning and its real-world impact, he enjoys exploring how AI and ML innovations are transforming businesses and shaping the future of technology. He frequently shares insights on the latest trends in the AI/ML space.