The Challenges of Deep Learning in Time-Series Forecasting and How Neural Networks Learn Temporal Awareness.

Introduction: Why Deep Learning Struggles with Time
Time-series forecasting is critical in domains like finance, energy, healthcare, and climate modeling. Traditionally, statistical models such as ARIMA, VAR, and Kalman Filters have been the dominant approaches because they explicitly model temporal dependencies. However, deep learning has gained popularity due to its ability to handle complex, large-scale datasets.
Yet, despite its promise, deep learning faces a fundamental limitation in time-series forecasting: it lacks an inherent understanding of time. Unlike images, where convolutional networks capture spatial patterns, or structured data, where relationships are explicitly defined, time-series data is inherently sequential. Standard feedforward neural networks process each input independently, ignoring the order in which data points occur.
Key Problems with Standard Neural Networks for Time-Series
- No Concept of Sequential Order — A typical neural network treats each input as an independent vector, ignoring past observations.
- Permutation Invariance — Neural networks assume feature positions can be swapped without affecting output, which is not true for time-series data.
- Fixed Input Size — Standard architectures require a fixed input length, making them inflexible for real-world time-series data with varying durations.
- Lack of Memory — Feedforward models do not retain information from previous time steps, making them incapable of capturing long-term dependencies.
To address these challenges, specialized architectures have been developed to introduce temporal awareness into deep learning models. Let’s explore these architectures and the feature engineering techniques that help them make sense of time.
How Deep Learning Models Learn Temporal Awareness
1. Recurrent Neural Networks (RNNs): Introducing Sequential Memory
RNNs introduce hidden states that carry information from previous time steps, enabling the model to recognize sequential dependencies. Each new input modifies the hidden state, allowing past observations to influence the current prediction.
.png)
RNN Architecture Logic
Why RNNs Struggle with Long-Term Dependencies
Despite their ability to track short-term patterns, RNNs face vanishing gradient problems when trying to capture long-term dependencies. As information propagates backward through time, gradient values shrink, making it difficult to adjust earlier layers effectively.
Feature Engineering for RNNs
- Lag Features — Including previous observations as explicit input features helps compensate for RNNs’ memory limitations.
- Normalization — Standardizing time-series data prevents instability in gradient updates.
- Cyclical Encoding — Transforming time-based features (e.g., hour of the day, day of the week) into sine-cosine pairs enhances the model’s ability to detect periodic patterns.
2. Long Short-Term Memory Networks (LSTMs): Solving Vanishing Gradients
LSTMs extend RNNs by introducing gating mechanisms that control information flow through a cell state, which serves as long-term memory. These gates determine what information to retain, update, or forget, allowing LSTMs to track long-range dependencies effectively.
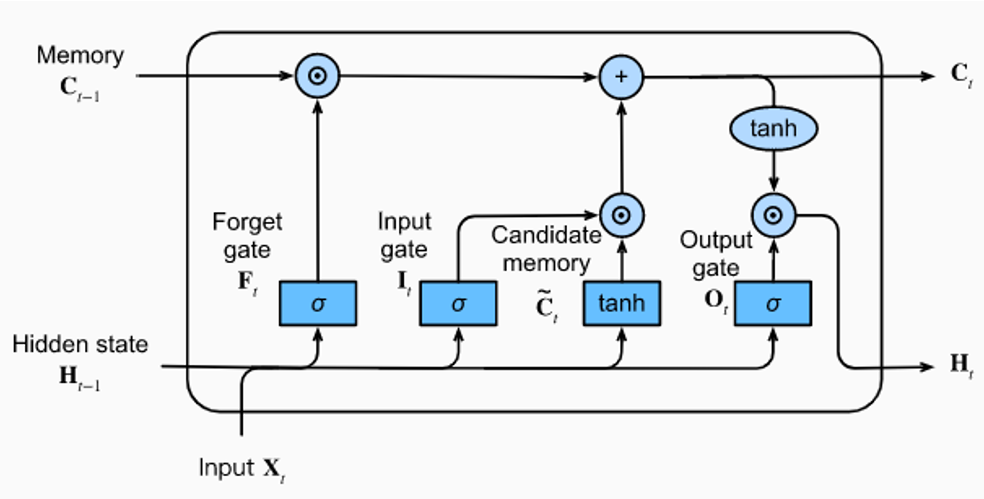
LSTM Architecture Logic
How LSTM Gates Work
- Forget Gate — Decides which past information to discard.
- Input Gate — Determines what new information should be added.
- Output Gate — Controls what gets passed to the next time step.
By dynamically adjusting memory retention, LSTMs mitigate the vanishing gradient problem and improve sequence modeling.
Feature Engineering for LSTMs
- Rolling Averages & Volatility Measures — Providing moving averages helps the model capture trend-based signals.
- Multi-Granularity Time Features — Including different time lags (e.g., daily, weekly, monthly) allows LSTMs to recognize patterns at multiple scales.
- Cyclical Encoding — Representing seasonal patterns with sine and cosine transformations enhances learning efficiency.
3. Gated Recurrent Units (GRUs): A Lightweight Alternative to LSTMs
GRUs simplify LSTMs by combining the forget and input gates into a single update gate, reducing computational overhead. This streamlined approach makes GRUs computationally efficient while still retaining long-term dependencies.
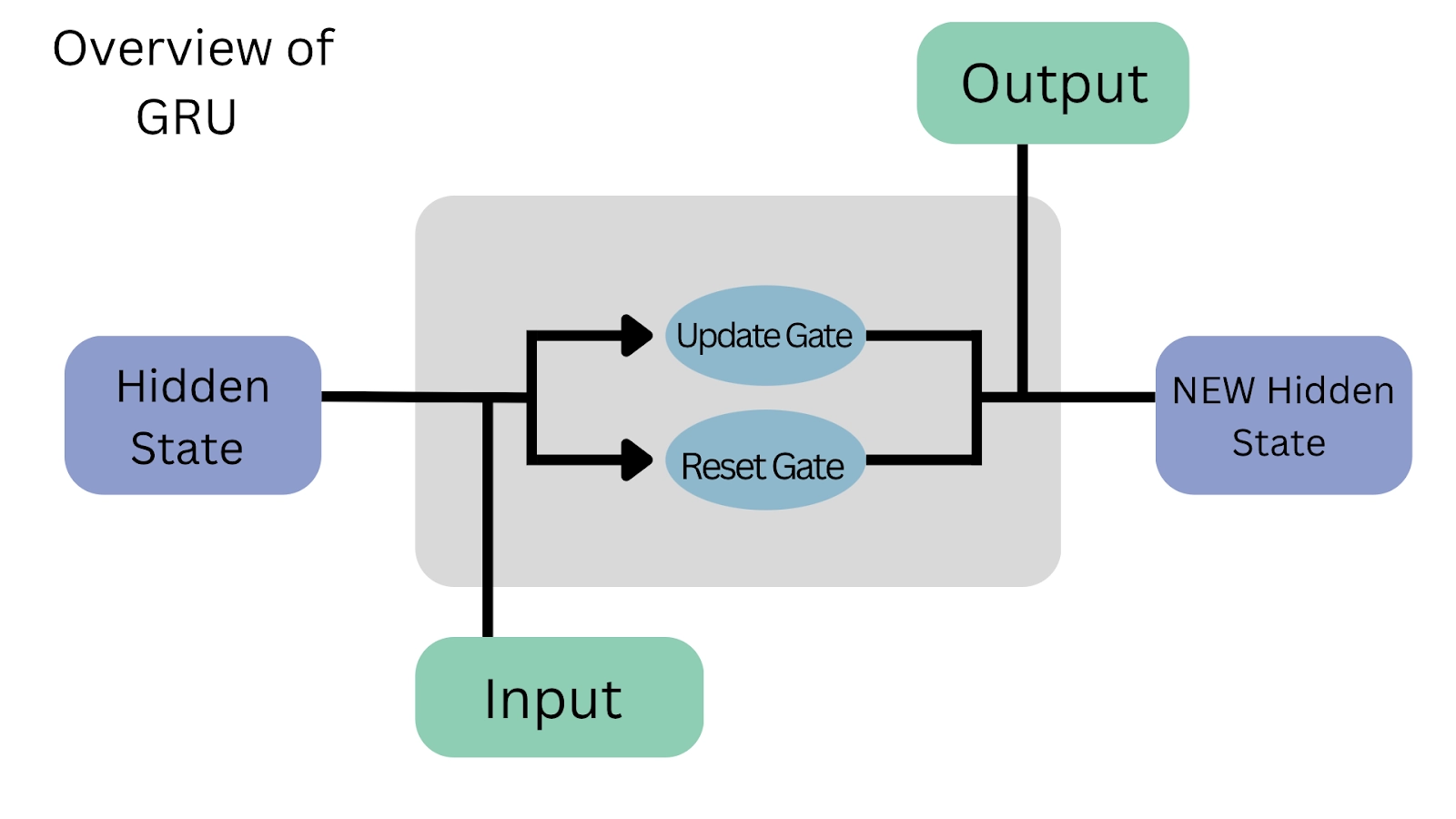
GRU Architecture Logic
How GRUs Improve Efficiency
- The update gate controls the balance between retaining past information and incorporating new inputs.
- The reset gate determines how much past context should be considered in generating the next hidden state.
GRUs often achieve similar performance to LSTMs but train faster, making them a practical choice for medium-sized time-series datasets.
Feature Engineering for GRUs
- Exponential Moving Averages — Smoothing historical data aids in capturing trends.
- Differencing Features — Using first-order or second-order differences helps the model recognize seasonality changes.
4. Temporal Convolutional Networks (TCNs): Convolution for Time-Series
TCNs replace recurrent connections with 1D convolutional layers, processing sequences in parallel rather than sequentially. Unlike traditional convolutional networks, TCNs apply causal convolutions, ensuring predictions at time step tt only depend on past inputs.
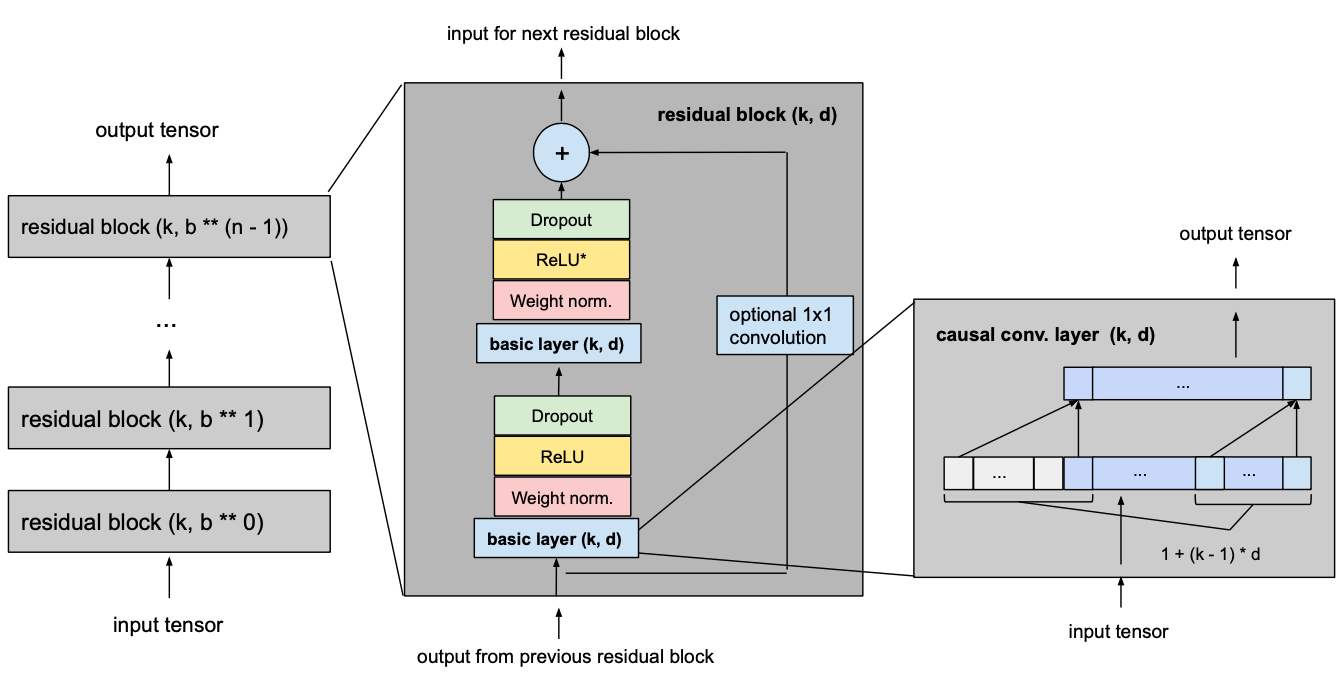
TCN Architecture Logic
Advantages of TCNs
- Faster Training — Convolutions allow for parallel computation, unlike sequential RNNs.
- Longer Memory — Dilation techniques expand the receptive field, enabling the model to capture long-term dependencies.
Feature Engineering for TCNs
- Wavelet Transforms — Capturing frequency-domain patterns enhances performance.
- Multi-Resolution Features — Using different convolution kernel sizes enables multi-scale learning.
5. Transformers for Time-Series: Attention Over Recurrence
Transformers, originally designed for NLP, replace recurrence with self-attention mechanisms that compare all time steps simultaneously. This allows them to model long-range dependencies without the constraints of sequential processing.
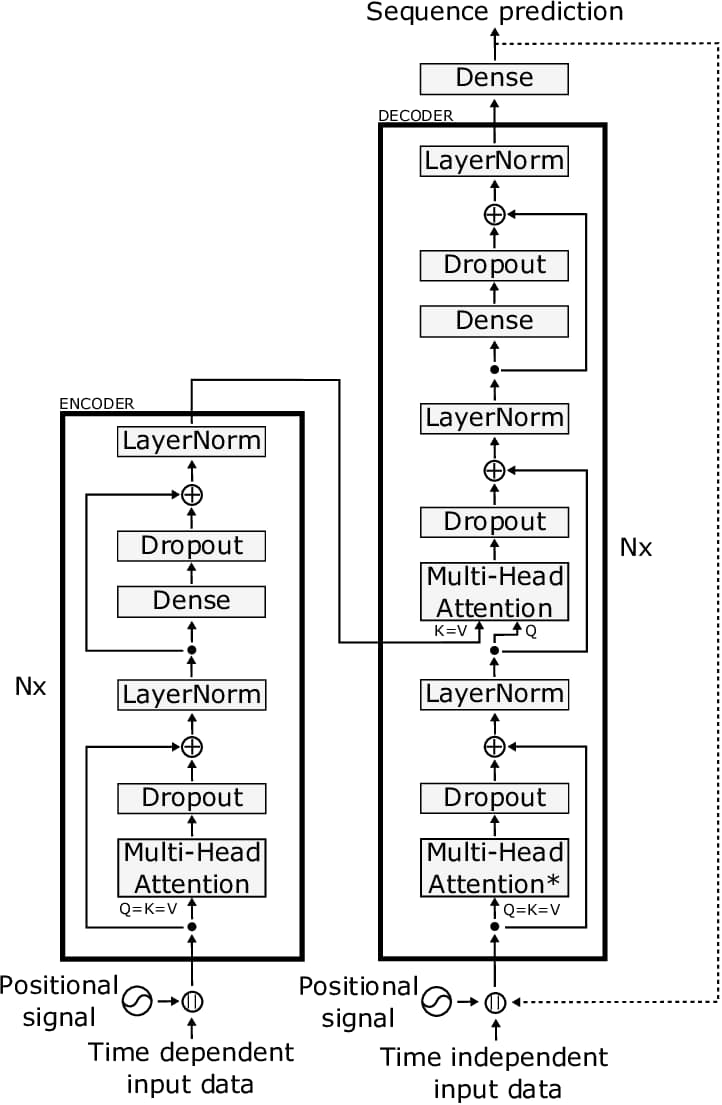
Transformer Architecture Logic
How Attention Mechanisms Work
Instead of processing sequences step by step, transformers compute relationships between all time steps at once. They assign attention scores that determine which past observations are most relevant to the current prediction.
Why Transformers Excel in Time-Series
- No Sequential Bottlenecks — Self-attention enables parallel computation, accelerating training.
- Global Context Awareness — Unlike RNNs, which rely on distant dependencies, transformers can weigh all past data points simultaneously.
Feature Engineering for Transformers
- Positional Encoding — Since transformers lack inherent order awareness, sine-cosine encoding is used to inject positional information.
- Fourier Transforms — Converting time-series data to frequency representations aids in detecting periodic patterns.
Conclusion: The Future of Deep Learning for Time-Series
Despite its challenges, deep learning is revolutionizing time-series forecasting. While RNNs, LSTMs, and GRUs introduce memory, newer architectures like TCNs and transformers push the boundaries of what’s possible. However, feature engineering remains crucial, as time-series forecasting benefits from well-crafted inputs that enhance temporal understanding.
Moving forward, the best results will likely come from hybrid approaches that blend deep learning with classical techniques, ensuring both interpretability and predictive power.
Get to know the Author:
Karan Bhutani is a Data Scientist Intern at Synogize and a master’s student in Data Science at the University of Technology Sydney. Passionate about machine learning and its real-world impact, he enjoys exploring how AI and ML innovations are transforming businesses and shaping the future of technology. He frequently shares insights on the latest trends in the AI/ML space.